Input files preperation
To run DeePKS-kit in connection with ABACUS, a bunch of input files are required so as to iteratively perform the SCF jobs on ABACUS and the training jobs on DeePKS-kit. Here we will use single water molecule as an example to show the required input files for the training of an LDA-based DeePKS model that provides PBE target energies and forces.
As can be seen in this example, 1000 structures of the single water molecules with corresponding PBE property labels (including energy and force) have been prepared in advance. Four subfolders, i.e., group.00-03 can be found under the folder systems. group.00-group.02 contain 300 frames each and can be applied as training sets, while group.03 contains 100 frames and can be applied as testing set.
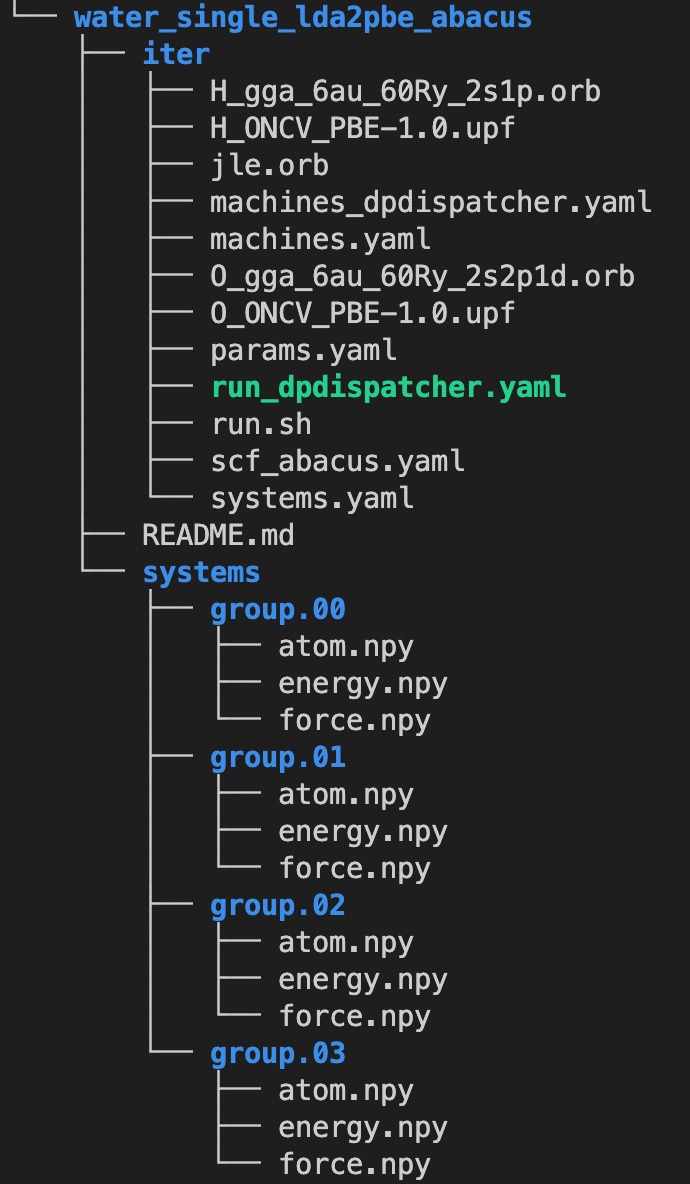
The prepared file structure of a ready-to-run DeePKS iterative traning process should basically look like
scf_abacus.yaml
This file controls the SCF jobs performed in ABACUS. The scf_abacus block controls the SCF jobs after the init iteration, i.e., with DeePKS model loaded, while the init_scf_abacus controls the initial SCF jobs, i.e., bare LDA or PBE SCF calculaiton. The reason to divide this file into two blocks is that after the init iteration, the SCF calculaitons with DeePKS model loaded are sometimes found hard to converge to a tight threshold, e.g., scf_thr = 1e-7. Therefore we might want to slightly loose that threshold after the init iteration. Also, even users need to train the model with force label, there is no need to calculate force during the init SCF cycle, since the init training will include the energy label only.
Below is a sample scf_abacus.yaml file for single water molecule, with the explanation of each keyword. Please refer to ABACUS input file documentation for a more detailed explanation of the input parameters in ABACUS.
scf_abacus:
# INPUT args; keywords that related to INPUT file in ABACUS
ntype: 2 # int; number of different atom species in this calculations, e.g., 2 for H2O
nbands: 8 # int; number of bands to be calculated; optional
ecutwfc: 50 # real; energy cutoff, unit: Ry
scf_thr: 1e-7 # real; SCF convergence threshold for density error; 5e-7 and below is acceptable
scf_nmax: 50 # int; maximum SCF iteration steps
dft_functional: "lda" # string; name of the baseline density functional
gamma_only: 1 # bool; 1 for gamma-only calculation
cal_force: 1 # bool; 1 for force calculation
cal_stress: 0 # bool; 1 for stress calculation
# STRU args; keywords that related to INPUT file in ABACUS
# below are default STRU args, users can also set them for each group in
# ../systems/group.xx/stru_abacus.yaml
orb_files: ["O_gga_6au_60Ry_2s2p1d.orb", "H_gga_6au_60Ry_2s1p.orb"] # atomic orbital file list for each element;
# order should be consistent with that in atom.npy
pp_files: ["O_ONCV_PBE-1.0.upf", "H_ONCV_PBE-1.0.upf"] # pseudopotential file list for each element;
# order should be consistent with that in atom.npy
proj_file: ["jle.orb"] # projector file; generated in ABACUS; see file desriptions for more details
lattice_constant: 1 # real; lattice constant
lattice_vector: [[28, 0, 0], [0, 28, 0], [0, 0, 28]] # [3, 3] matrix; lattice vectors
coord_type: "Cartesian" # "Cartesian" or "Direct"; the latter is for fractional coordinates
# cmd args; keywords that related to running ABACUS
run_cmd : "mpirun" # run command
abacus_path: "/usr/local/bin/abacus" # ABACUS executable path
# below is the init_scf_abacus block, which is basically same as above
# just note that the recommended value for scf_thr is 1e-7,
# and force calculation can be omitted since the init training includes energy label only.
init_scf_abacus:
orb_files: ["O_gga_6au_60Ry_2s2p1d.orb", "H_gga_6au_60Ry_2s1p.orb"]
pp_files: ["O_ONCV_PBE-1.0.upf", "H_ONCV_PBE-1.0.upf"]
proj_file: ["jle.orb"]
ntype: 2
nbands: 8
ecutwfc: 50
scf_thr: 1e-7
scf_nmax: 50
dft_functional: "lda"
gamma_only: 1
cal_force: 0
lattice_constant: 1
lattice_vector: [[28, 0, 0], [0, 28, 0], [0, 0, 28]]
coord_type: "Cartesian"
#cmd args
run_cmd : "mpirun"
abacus_path: "/usr/local/bin/abacus"
For multi k-points systems, the number of k-points can either be set explicitly as:
scf_abacus:
<...other keywords>
k_points: [4,4,4,0,0,0]
init_scf_abacus:
<...other keywords>
k_points: [4,4,4,0,0,0]
or via kspacing as:
scf_abacus:
<...other keywords>
kspacing: 0.1
init_scf_abacus:
<...other keywords>
kspacing: 0.1
machine.yaml
Note
This file is not required when running jobs on Bohrium via DPDispachter. In such case, users need to prepare machine_dpdispatcher.yaml instead.
To run ABACUS-DeePKS training process on a local machine or on a cluster via slurm or PBS, it is recommended to use the DeePKS built-in dispatcher and prepare machine.yaml file as follows.
# this is only part of input settings.
# should be used together with systems.yaml and params.yaml
scf_machine:
group_size: 125 # number of SCF jobs that are grouped and submitted together; these jobs will be run sequentially
resources:
task_per_node: 1 # number of CPUs for one SCF job
sub_size: 1 # keyword for PySCF; set to 1 for ABACUS SCF jobs
dispatcher:
context: local # "local" to run on local machine, or "ssh" to run on a remote machine
batch: shell # set to shell to run on local machine, you can also use `slurm` or `pbs`
train_machine:
dispatcher:
context: local # "local" to run on local machine, or "ssh" to run on a remote machine
batch: shell # set to shell to run on local machine, you can also use `slurm` or `pbs`
remote_profile: null # use lazy local
# resources are no longer needed, and the task will use gpu automatically if there is one.
python: "python" # use python in path
# other settings (these are default; can be omitted)
cleanup: false # whether to delete slurm and err files
strict: true # do not allow undefined machine parameters
#paras for abacus
use_abacus: true # use abacus in scf calculation
To run ABACUS-DeePKS via PBS or slurm, the following parameters can be specified under resources block in both scf_machine and train_machine:
# this is only part of input settings.
# should be used together with systems.yaml and params.yaml
scf_machine:
<...other kerwords>
resources:
numb_node: # int; number of nodes; default value is 1
task_per_node: # int; ppn required; default value is 1;
numb_gpu: # int; number of GPUs; default value is 1
time_limit: # time limit; default value is 1:0:0
mem_limit: # int; memeory limit in GB
partition: # string; queue name
account: # string; account info
qos: # string;
module_list: # e.g., [abacus]
source_list: # e.g., [/opt/intel/oneapi/setvars.sh; conda activate deepks]
<... other keywords>
train_machine:
<...other kerwords>
resources:
<... same as above>
machine_dpdispatcher.yaml
Note
This file is not required when running jobs on a local machine or on a cluster via slurm or PBS with the built-in dispatcher. In such case, users may prepare machine.yaml instead. That being said, users may also modify keywords in this file to submit jobs to a cluster via slurm or PBS. Please refer to DPDispatcher documentation for more details on slurm/PBS job submission.
To run ABACUS-DeePKS on Bohrium or via slurm, users need to use DPDispatcher and prepare machine_dpdispatcher.yaml file as follows. Most of the keyword in this file share the same meaning as those in machine.yaml. The unique part here is to specify keywords in dpdispatcher_resources: block. Below is an example for running jobs in Bohrium:
# this is only part of input settings.
# should be used together with systems.yaml and params.yaml
scf_machine:
resources:
task_per_node: 4
dispatcher: dpdispatcher
dpdispatcher_resources:
number_node: 1
cpu_per_node: 8
group_size: 125
source_list: [/opt/intel/oneapi/setvars.sh]
sub_size: 1
dpdispatcher_machine:
context_type: lebesguecontext
batch_type: lebesgue
local_root: ./
remote_profile:
email: (your-account-email) # email address registered on Bohrium
password: (your-passward) # password on Bohrium
program_id: (your-program-id) # program ID on Bohrium
input_data:
log_file: log.scf
err_file: err.scf
job_type: indicate
grouped: true
job_name: deepks-scf
disk_size: 100
scass_type: c8_m8_cpu # machine type
platform: ali
image_name: abacus-workshop # image name
on_demand: 0
train_machine:
dispatcher: dpdispatcher
dpdispatcher_machine:
context_type: lebesguecontext
batch_type: lebesgue
local_root: ./
remote_profile:
email: (your-account-email)
password: (your-passward)
program_id: (your-program-id)
input_data:
log_file: log.train
err_file: err.train
job_type: indicate
grouped: true
job_name: deepks-train
disk_size: 100
scass_type: c8_m8_cpu
platform: ali
image_name: abacus-workshop
on_demand: 0
dpdispatcher_resources:
number_node: 1
cpu_per_node: 8
group_size: 1
source_list: [~/.bashrc]
python: "/usr/bin/python3" # use python in path
# resources are no longer needed, and the task will use gpu automatically if there is one
# other settings (these are default; can be omitted)
cleanup: false # whether to delete slurm and err files
strict: true # do not allow undefined machine parameters
#paras for abacus
use_abacus: true # use abacus in scf calculation
params.yaml
This file controls the init and iterative training processes performed in DeePKS-kit. Default values for hyperparameters set for the training process (as given below) are recommended for users who are not very experienced in machine-learning, while machine-learning gurus are welcome to play with them.
# this is only part of input settings.
# should be used together with systems.yaml and machines.yaml
# number of iterations to do, can be set to zero for DeePHF training
n_iter: 1
# directory setting (these are default choices, can be omitted)
workdir: "."
share_folder: "share" # folder that stores all other settings
# scf settings, set to false when n_iter = 0 to skip checking
scf_input: false
# train settings for training after init iteration,
# set to false when n_iter = 0 to skip checking
train_input:
# model_args is omitted, which will inherit from init_train
data_args:
batch_size: 16 # training batch size; 16 is recommended
group_batch: 1 # number of batches to be grouped; set to 1 for ABACUS-related training
extra_label: true # set to true to train the model with force, stress, or bandgap labels.
# note that these extra labels will only be included after the init iteration
# only energy label will be included for the init training
conv_filter: true # if set to true (recommended), will read the convergence data from conv_name
# and only use converged datapoints to train; including any unconverged
# datapoints may screw up the training!
conv_name: conv # npy file that records the converged datapoints
preprocess_args:
preshift: false # restarting model already shifted. Will not recompute shift value
prescale: false # same as above
prefit_ridge: 1e1 # the ridge factor used in linear regression
prefit_trainable: false # make the linear regression fixed during the training
train_args:
# start learning rate (lr) will decay a factor of `decay_rate` every `decay_steps` epoches
decay_rate: 0.5
decay_steps: 1000
display_epoch: 100 # show training results every n epoch
force_factor: 1 # the prefactor multiplied infront of the force part of the loss
n_epoch: 5000 # total number of epoch needed in training
start_lr: 0.0001 # the start learning rate, will decay later
# init training settings, these are for DeePHF task
init_model: false # do not use existing model to restart from
init_scf: True # whether to perform init SCF;
init_train: # parameters for init nn training; basically the same as those listed in train_input
model_args:
hidden_sizes: [100, 100, 100] # neurons in hidden layers
output_scale: 100 # the output will be divided by 100 before compare with label
use_resnet: true # skip connection
actv_fn: mygelu # same as gelu, support force calculation
data_args:
batch_size: 16
group_batch: 1
preprocess_args:
preshift: true # shift the descriptor by its mean
prescale: false # scale the descriptor by its variance (can cause convergence problem)
prefit_ridge: 1e1 # do a ridge regression as prefitting
prefit_trainable: false
train_args:
decay_rate: 0.96
decay_steps: 500
display_epoch: 100
n_epoch: 5000
start_lr: 0.0003
Even though the DeePKS training scheme is relativley robust, there might be a chance that the SCF procedure fails to converge after loading the DeePKS model. Such convergence failure might be caused by insufficient variety of the training data, and/or the discontinuities issue due to the sorting of the eigenvalues in eigenvalue decomposition step when constructing the descriptors. One thing that worths trying is to add more training data with sufficient variety in structure, and if the convergence failure remains or the training data is indeed sufficient, users may further symmetrize the descriptors by modifing the init_train block in params.yaml as follows:
init_train: # parameters for init nn training; basically the same as those listed in train_input
proj_basis: [[0,[0,...,0]],
[1, [0,...,0]],
[2, [0,...,0]]] # projected basis for thermal embedding, 0, 1, and 2 in the first column correspond to s, p, and d orbitals,
# and the number of zeros afterwards should equal the number of Bessel functions in jle.orb.
model_args:
hidden_sizes: [100, 100, 100] # neurons in hidden layers
output_scale: 100 # the output will be divided by 100 before compare with label
use_resnet: true # skip connection
actv_fn: mygelu # same as gelu, support force calculation
embedding: {embd_sizes: null, init_beta: 5, type: thermal} # apply thermal averaging to further symmetrize the descriptors
<...other keywords>
projector file
The descriptors applied in DeePKS model is generated from the projected density matrix, therefore a set of projectors are required in advance. To obtain these projectors for periodic system, users need to run a specific sample job in ABACUS. These projectors are products of spherical Bessel functions (radial part) and spherical harmonic functions (angular part), which are similar to numerical atomic orbitals. The number of Bessel functions are controled by the radial and wavefunction cutoff, for which 5 or 6 Bohr and ecutwfc set in scf_abacus.yaml are recommeded, respectively.
Note that it is not necessary to change the STRU file of this sample job, since all elements share the same descriptor. Basically, users only need to specify calculation as gen_bessel and then adjust the energy cutoff and the radial cutoff of the wavefunctions. The angular part is controled via the keyword bessel_lmax and the value 2 (including s, p, and d orbitals) is strongly recommended. See below for related input parameters:
calculation gen_bessel # calculation type should be gen_bessel
bessel_lmax 2 # maximum angular momentum for projectors; 2 is recommended
bessel_rcut 5 # radial cutoff in unit Bohr; 5 or 6 is recommended
ecutwfc 100 # kinetic energy cutoff in unit Ry; should be consistent with that set for ABACUS SCF calculation
After running this sample job, users will find jle.orb in folder OUT.abacus and will need to copy this file to the iter folder.
Note
Note that the jle.orb file provided in the example is with extremely low cutoff for efficient job running and therefore is not indended for any practical production-level projects. Users need to generate a more practical projector file based on the recommended cutoffs provided above.
orbital files and pseudopotential files
The DeePKS-related calculations are implemented with lcao basis set in ABACUS, therefore the orbital and pseudopotential files for each elements are required. Since the numerical atomic orbitals in ABACUS are generated based on SG15 optimized Norm-Conserving Vanderbilt (ONCV) pseudopotentials, users are required to use this set of pseudopotentials. Atomic orbitals with 100Ry energy cutoff are recommended, and ewfcut is recommended to set to 100 Ry, i.e., consistent with the one applied in atomic orbital generation.
Both the pseudopotential and the atomic orbital files can be downloaded from ABACUS official website. The required files are recommended to be placed on iter folder, as shown in the file structure .